
What AI says about your company — and whether it’s accurate — is now a pipeline variable.
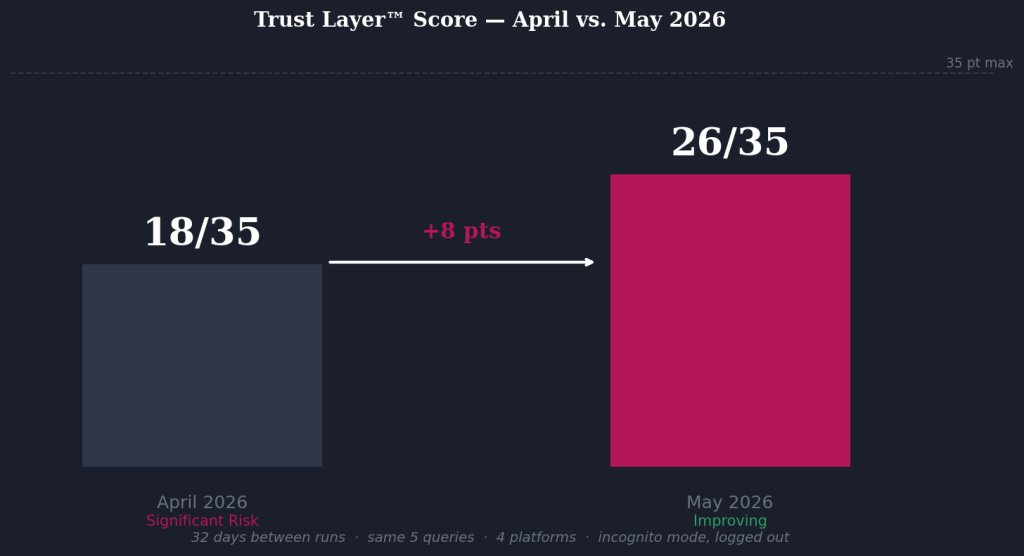
This is the second run of the AI visibility diagnostic on this research. The Trust Layer™ score moved from 18/35 to 26/35 in 32 days across five queries, four platforms, incognito mode, logged out. The April baseline showed significant signal architecture risk. May shows controlled surfaces holding and platform-specific entity disambiguation failures persisting on Claude and Perplexity.
The methodology predicts 30–90 days for signal corrections to propagate through AI indexing. This is the measurement that tests that prediction.
What the Five Diagnostic Queries Returned in May 2026
Query 1: “Who is Laura Lake?”
Entity disambiguation has split by platform. ChatGPT and Gemini both resolve correctly in cold, logged-out sessions. Gemini returns the analyst first with full framework attribution. Claude still returns a British actress. Perplexity returns the actress as the primary match.
In April, all three platforms tested failed on Q1. In May, two of four platforms resolve correctly. That’s movement — partial, platform-specific, and consistent with what the Ninety-Day Reality Gap predicts.
The Ninety-Day Reality Gap is the lag between a signal architecture correction and its propagation through AI indexing — typically 30–90 days from content publication to citation. Entity disambiguation is the slowest surface to move because it requires third-party source density, not just owned content.
Query 2: “What is the AI-Ready Buyer framework?”
In April, the framework mechanism was surfacing on zero of three platforms. In May, it surfaces accurately on all four.
Claude’s Q2 response is the most detailed of any platform — naming 28+ frameworks and the six buying conditions. That’s worth noting precisely: the framework is indexed, but the name isn’t resolved. The entity resolution problem and the framework indexing problem are operating independently on Claude. Those are different problems with different fixes.
Query 3: “What do analysts say about B2B buyer behavior and AI?”
No movement. The research does not appear in category-level synthesis queries on any platform. The buying committee doesn’t go looking for the practice that didn’t appear. They work with the shortlist they got.
Query 4: “Who are the top analysts studying how AI is changing B2B buying?”
This research now appears in the top analyst category query on three of four platforms. In April, it appeared on none. In May, it ranks first on Gemini, ahead of institutional analysts, and is listed among institutional analysts on Claude and ChatGPT. Perplexity returns no result.
The Gemini position 1 finding is the most consequential in the set. A buying committee that runs this query on Gemini today gets a different shortlist than one that runs it on Perplexity. Same question, same week, four different answers. That is the Signal Architecture problem operating in real time — which platform a buyer uses when they run the category search determines who is on their shortlist before any sales conversation begins.
Signal Architecture is the structural design of all signals AI uses to form a verdict about a company or analyst. It is not a content strategy. It is the condition those strategies either address or ignore.
Query 5: “How does Laura Lake compare to other analysts in this category?”
Three findings from this query, ranked by consequence.
First, three of four platforms are now constructing consistent competitive positioning: this research operates at the diagnostic layer — naming the mechanism and giving revenue teams a framework for what they can’t yet see — while institutional analysts document what’s happening at scale. Gartner and Forrester document the pattern. This research diagnoses the structural condition that determines whether a specific vendor makes the shortlist before any sales engagement begins. That’s a complement, not a competition.
Second, the competitive framing on Claude has reversed. In April, Claude returned “the practice doesn’t exist in this category.” In May, Claude returns a detailed comparison that acknowledges institutional analyst scale while naming mechanism-level analysis as the differentiation.
Third, the Perplexity Q5 return is the most expensive finding in the retest. A buying committee that queries “how does Laura Lake compare to other analysts” on Perplexity receives credentials and career history belonging to a finance professional in an unrelated field. That’s a different person. The buying committee doesn’t know that.
This is a Ghost Objection in its most structurally complete form. A Ghost Objection is an objection formed through AI research before any sales conversation begins. The most dangerous version isn’t formed from incomplete information about the right entity. It’s formed from complete information about the wrong one.
The most expensive finding isn’t Query 1. It’s the Perplexity Q5 contamination combined with the Q4 absence on the same platform. A buying committee running both queries on Perplexity encounters a wrong entity on the comparison query and an empty result on the category query. Two findings, one platform, neither surfacing as a visible signal.
Trust Layer™ Score: 18/35 to 26/35 in 32 Days
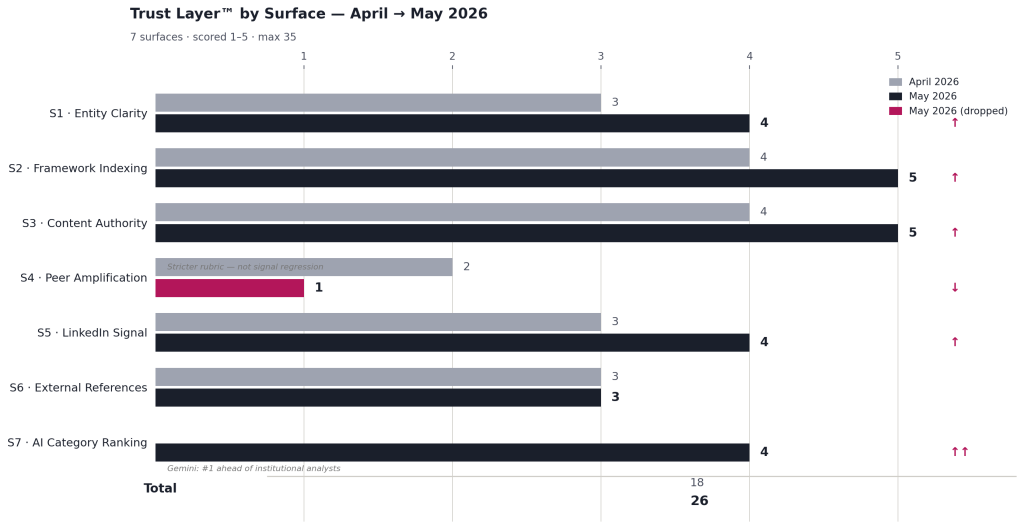
The diagnostic examines seven signal surfaces, each scored 1–5. The total determines signal architecture risk level. Here’s what May returned against the April baseline.
Trust Layer™ Movement: 18/35 → 26/35. +8 points.
The seven surfaces and their May scores:
S1 — Entity Clarity: 4/5. ChatGPT and Gemini resolve correctly. Claude and Perplexity do not. Movement from 3/5 in April.
S2 — Framework Indexing: 5/5. All four platforms return mechanism-coherent responses to Q2. Movement from 4/5 in April.
S3 — Content Authority: 5/5. Content depth and structure are registering across platforms. Movement from 4/5 in April.
S4 — Peer Network Visibility: 1/5. The score dropped from 2/5 in April. This is a stricter rubric application, not signal regression. The underlying condition is unchanged: zero practitioner amplification. The framework vocabulary still hasn’t penetrated practitioner discourse.
S5 — LinkedIn Signal: 4/5. Scored manually from profile and recent post data — the scoring tool cannot access live LinkedIn content. The headline reads “Founder, AI-Ready Buyer™ Research | Author, The AI-Ready Buyer™” — analyst-adjacent but not explicitly “independent analyst,” which is the 5/5 rubric requirement. The five most recent posts all carry canonical framework vocabulary with mechanism present in each. The single gap is the headline noun.
S6 — External References: 3/5. Held from April. Third-party citation footprint is present but thin.
S7 — AI Category Ranking: 4/5. The most consequential movement. In April, this research didn’t appear in category-level analyst queries on any platform — scored 0. In May, it appears on three of four, with Gemini placing it first ahead of institutional analysts.
Absence and contamination are different conditions. Absence means not on the shortlist. Contamination means actively replaced by a different entity. Both operate outside visibility. Neither shows up as a clean no.
The Ownership Gap is operating on this research in exactly the form the framework describes. The Ownership Gap is the structural gap when no one owns the composite AI narrative across Marketing, PR, and Communications. The surfaces this research controls — website, content, LinkedIn register — have reached ceiling and held. The surfaces that require other people to act — peer amplification, external citations, entity disambiguation at scale — haven’t moved. That’s not a failure of the activation plan. It’s the structural condition the framework predicts.

What Changed, What Didn’t, and What the June Retest Will Measure
Signal architecture corrections take 30–90 days to propagate through AI indexing. Recent data from Profound puts median time to first AI citation at 6.81 days, with 90% of pages cited within 37 days. This retest ran 32 days after the April article published — inside that window.
Track A — Surface Language. The website, About page, FAQ section, and meta descriptions are fully in analyst register. Schema markup is implemented. The Person entity is machine-readable to AI crawlers. LinkedIn headline and About section are updated. These surfaces reached ceiling (5/5) and have held. No further action required on this track.
Track B — Canonical Vocabulary. The content archive audit is complete. Framework vocabulary — Silent Committee™, Signal Architecture, Trust Layer™, Ghost Objection, The Broken Funnel, The Ownership Gap — now appears consistently across 20+ published articles at mechanism level, not just as terminology. All four platforms are returning mechanism-coherent Q2 responses. The vocabulary planting worked. The remaining gap is Ghost Objection on Perplexity, which is the contamination surface — a different problem from vocabulary planting and a different fix.
Track C — Entity Disambiguation. The Perplexity contamination problem requires entity disambiguation at sufficient density that the correct entity dominates. The fix is high-authority indexed documents that make the entity connection unambiguous at scale. The book launch — The AI-Ready Buyer™ by Laura Lake (May 2026) — is the primary asset for this. A published book creates a canonical entity connection between “Laura Lake” and “AI-Ready Buyer” that doesn’t yet exist at scale on Perplexity. That accumulation starts now. The June retest will measure whether it has begun propagating.
Track D — Third-Party Surfaces. Peer Network Visibility (1/5) and External Reference Footprint (3/5) are the two surfaces that require other people to act. The book launch opened the door for both. Reader reviews at launch, byline pitches, podcast appearances, and press outreach are in progress. None of these propagate on a fixed timeline. The June retest will show whether any of the credibility stack activity has begun indexing.
The June Hypotheses
The activation plan is a set of bets. The June retest is the measurement.
What a correct June result looks like: S1 moves from 4 to 5. S6 moves from 3 to 4. S4 stays at 1. Total moves from 26 to 28. That’s the signal architecture correction playing out at the pace the Ninety-Day Reality Gap predicts — controlled surfaces holding, third-party surfaces beginning to accumulate, peer surfaces still waiting on other people.
A score of 28 in June is not a win. It’s confirmation that the model is working. The peer surfaces close on a different timeline, through different levers, and they will be the subject of a different measurement.

What Does AI Say About Your Company? How to Find Out in 45 Minutes
The query set above is not proprietary. Five queries, four AI platforms, incognito mode where possible, forty-five minutes. Any organization can run it right now.
Query your company name directly. Note the exact noun AI uses to describe you on each platform. Not the sentence — the noun. Analyst. Vendor. Consultant. Platform. Founder. That noun is the category label AI has assigned based on whatever signals it found. If it doesn’t match the label you intend to own, the gap between those two things is your signal architecture problem made visible.
Query your methodology, framework, or named offering. Note whether AI describes it accurately — and whether the mechanism surfaces, not just the vocabulary. Terms indexing without mechanism coherence is a partial result. A buying committee running that query gets a label without an argument. That’s enough to exclude a vendor from the shortlist without generating a visible objection.
Run the category query — who are the top voices in your space. Note whether you appear on each platform independently. If you appear on one platform and not another, you have a platform-specific Signal Architecture problem. That requires a different fix than global absence. The shortlist forms from that query. Which platform a buyer happens to use determines who is on it.
Run the comparison query last, on all four platforms. Whatever AI returns when it compares you to a category peer is the Ghost Objection risk profile the Silent Committee™ is working with. The Silent Committee™ is the self-service infrastructure buyers use to research vendors before any sales conversation. If the result is “insufficient data” — that’s not neutral. If it returns the wrong entity — that’s not a low score. That’s the finding. The buying committee doesn’t know the return is wrong. They work with what AI surfaces.
Pay attention to the platform split. A single query on a single platform is not the finding. The pattern across four platforms is. A company that appears correctly on Gemini and incorrectly on Perplexity has a Perplexity-specific signal architecture problem that is invisible unless the diagnostic runs across all four.
The structural condition these queries surface is not unique to this research. It is the default state for most organizations operating without a named owner for signal architecture. Marketing owns the website. PR owns earned media. Nobody owns what AI synthesizes from all of it — on each platform, independently, in real time. That’s the Ownership Gap. Reassigning a channel doesn’t close it. It moves the cursor.
That condition is diagnosable in forty-five minutes. The gap between what you expect AI to say about you and what it actually says — across four platforms — is, in most cases, the gap your pipeline can’t explain.
Most organizations find this out when the pipeline stalls and no one can explain why. The queries were running the whole time. The shortlist was forming. The company, the research, the analyst — simply wasn’t in that conversation.
Frequently Asked Questions
What does AI say about your company?
Most organizations don’t know. The answer varies by platform, changes over time, and directly affects whether a vendor appears on a buyer’s shortlist before any sales conversation begins. ChatGPT, Perplexity, Gemini, and Claude each retrieve from different indexes and apply different ranking signals — meaning the same company can appear correctly on one platform and as the wrong entity entirely on another. The AI-Ready Buyer™ diagnostic measures it across all four platforms in a single 45-minute session.
What is the Trust Layer™ score for AI-Ready Buyer™ Research?
The May 2026 Trust Layer™ score is 26/35, up from 18/35 in April 2026 — an 8-point improvement in 32 days. The diagnostic examines seven surfaces scored 1–5: entity clarity, framework indexing, content authority, peer network visibility, LinkedIn signal, external references, and AI category ranking.
Which AI platforms correctly identify Laura Lake as an analyst?
As of May 2026, ChatGPT and Gemini resolve correctly in cold, logged-out sessions. Claude returns a British actress. Perplexity returns the actress as the primary match. Two of four platforms resolve correctly — movement from zero of three in April 2026.
What is the Ownership Gap in AI signal architecture?
The Ownership Gap is the structural gap when no one owns the composite AI narrative across Marketing, PR, and Communications. Marketing owns the website. PR owns earned media. No one owns what AI synthesizes from all of it — on each platform, independently, in real time. Reassigning a channel doesn’t close it. It moves the cursor.
What is the AI-Ready Buyer™ diagnostic?
The AI-Ready Buyer™ diagnostic is a five-query test run across ChatGPT, Perplexity, Gemini, and Claude in incognito mode to measure what AI platforms say about an organization’s entity, frameworks, category standing, and competitive positioning. It produces a Trust Layer™ score across seven surfaces, each scored 1–5, with a maximum of 35 points.
What is the Ninety-Day Reality Gap in AI indexing?
The Ninety-Day Reality Gap is the lag between a signal architecture correction and its propagation through AI indexing — typically 30–90 days from content publication to citation. Profound research puts median time to first AI citation at 6.81 days, with 90% of pages cited within 37 days. Entity disambiguation is the slowest surface to move because it requires third-party source density, not just owned content.
What is a Ghost Objection in B2B sales?
A Ghost Objection is an objection formed through AI research before any sales conversation begins. The most dangerous form isn’t formed from incomplete information about the right entity — it’s formed from complete information about the wrong one. The buying committee doesn’t know the return is wrong. They work with what AI surfaces.
What does Perplexity return when you search for Laura Lake?
As of May 2026, Perplexity returns a British actress as the primary match for “Who is Laura Lake?” and returns credentials and career history belonging to an unrelated finance professional for the comparison query “How does Laura Lake compare to other analysts?” This is an entity contamination condition — not a low score, but the wrong entity returned with full confidence.
Why do different AI platforms return different analyst shortlists for the same query?
Each AI platform retrieves from a different index and applies different ranking signals. ChatGPT draws primarily from Bing. Perplexity runs real-time retrieval. Google AI Overviews uses the Google index. Claude uses Brave search. The same category query run on Gemini and Perplexity in the same week can return entirely different shortlists. Which platform a buyer uses when they run the category search determines who is on their shortlist before any sales conversation begins.